近年、音声をテキストに変換する文字起こしツールの需要が急速に高まっています。
その中でも注目を集めているのが、AI技術を駆使した「Whisper」です。
多くの企業や個人が、効率的な業務遂行やコンテンツ制作のためにこのツールを活用しています。
しかし、初めて利用する方にとっては、どのように使えば良いのか、また実際の価格がどれくらいなのかが気になるポイントですよね。
この記事では、Whisperの基本的な使い方から無料で試せる方法、さらには具体的な料金体系について詳しく解説します。
[su_note note_color=”#FEFFE0″]
AIを使って効率的にブログ記事・SEOコンテンツを作成したいのであればAItoolsを利用するのがおすすめです。
今なら5日間の無料トライアルもご用意しているので、AIライティングに興味がある人はぜひチェックしてください。
[/su_note]
Whisperとは?

[su_box title=”Whisperの特徴” box_color=”#339FDB”]
- 多言語対応のリアルタイム文字起こし
- 音声コマンドの認識と実行
- ノイズキャンセリング機能
- 会議録の自動生成
- 複数の話者を認識して発言者ごとにテキストを区分できる
[/su_box]
Whisperは、OpenAIが開発した先進的な、音声データを「文字起こし」するためのツールです。
「文字起こし」の分野で高い精度を誇り、複数の言語に対応しています。
Whisperは「ディープラーニング」を活用しており、音声データをテキストに変換する際、雑音や背景音を効果的に除去します。
この技術により、従来の音声認識システムでは難しかった環境下でも高い精度を実現しています。
また、Whisperは「クラウドベース」のサービスとして提供されており、ユーザーはインターネットを通じて簡単にアクセス可能です。
ノイズキャンセリング機能、そして高いセキュリティレベルが認められています。
これにより、ビジネスシーンや教育現場、さらには個人利用においても幅広く活用されています。
さらに、WhisperのAPIを利用することで、他のアプリケーションやサービスと連携させることも容易です。
日本市場においても、Whisperは「自動文字起こし」ツールとして注目を集めており、多くの企業が業務効率化のために導入を検討しています。
Whisperの音声認識モデルとは?

音声認識モデルは、音声をテキストに変換する技術の事です。
この技術は、自動音声認識(Automatic Speech Recognition, ASR)とも呼ばれ、特にディープラーニングの進化により大きな発展を遂げました。
音声認識モデルは、音声の音響的特徴と言語的特徴を解析し、それを基にテキストを生成します。
音響モデルは音声の周波数特性を捉え、言語モデルは音素の並びを解析します。
これにより、多様なアクセントや背景ノイズにも対応でき、高精度な認識が可能となります。
スマートアシスタントや音声操作アプリケーションなど、様々な分野で利用されています。
Whisperの使い方を3ステップで紹介

Whisperを使うためには下記手順が必要となります。
- Whisperの実行環境を準備する
- 必要なライブラリをインストールする
- GPUの設定を確認する
3つのステップについて詳しく紹介していきます。
1.Whisperの実行環境を準備する
Google Colaboratory(通称Colab)は、Pythonコードをクラウド上で実行できるGoogleが提供している無料のプラットフォームです。
WhisperをColabで利用するための準備は以下のステップで行います。
1. Colabにアクセスし、新しいノートブックを作成する
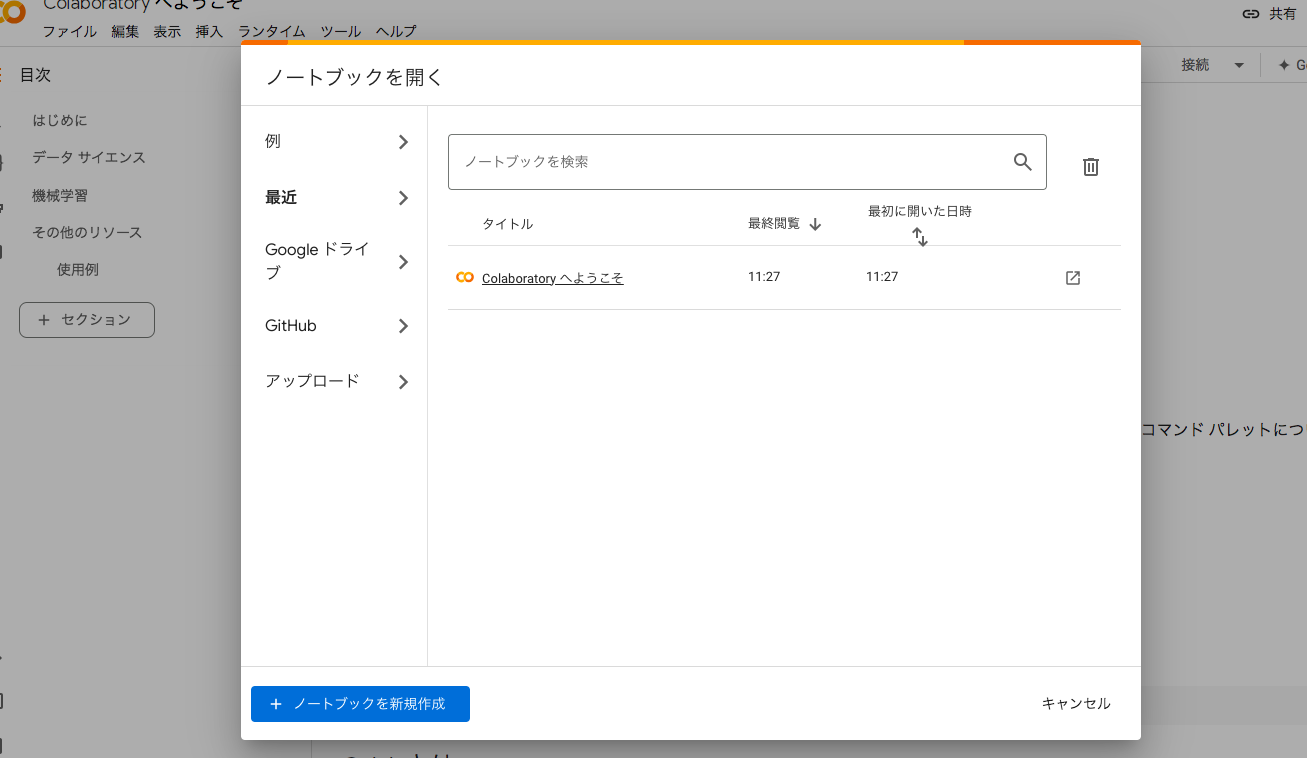
右上の「ファイル」メニューから「新しいノートブック」を選択します。
2. 必要なライブラリをインストールする
新しいコードセルを作成し、以下のコマンドを入力して実行。
!pip install torchaudio
このコマンドは、Whisperとその依存ライブラリをインストールします。
3. GPUの設定を確認する
Colabのメニューから
これをする事で、Whisperの処理速度が大幅に向上します。
これで環境設定は完了です。
2.読み込ませる音声ファイルを用意する
Whisperで処理するための音声ファイルを用意します。
Whisperで対応している音声ファイルは下記を参考にしてください。
高音質のファイルを使用することで音声認識の精度が向上するため、事前に音声ファイルの音質を確認し、必要があれば編集することで、認識精度をさらに高めることができます。
音声ファイルを準備したら、Whisperがアクセスできる場所に保存します。
また、長時間の音声ファイルの場合、適切な長さに分割しておくと、処理時間も短くなるのでおすすめです。
3.音声データをアップロードして文字起こしを行う
サイドバーの「ファイル」タブを開き、アップロードしたいファイルをドラッグ&ドロップをします。
アップロードが完了したら、Pythonコードを使用してWhisperモデルを呼び出し、音声ファイルを指定します。
下記のコードを記入します。
import whisper
model = whisper.load_model(“base”)
result = model.transcribe(“/content/your_audio_file.wav“)
print(result[“text”])
このコードでは、まずWhisperモデルをロードし、次にアップロードした音声ファイルのパスを指定して文字起こしを実行します。
「/content/your_audio_file.wav」※コードの赤文字部分は実際のファイルパスに置き換え。
処理が完了すると、音声がテキストに変換され、文字起こしが完了します。
Whisperの料金体系とプラン紹介

Whisperを利用するには、無料プラン・各有料プランがあります。
| プラン | できること | できないこと |
|---|---|---|
| 無料プラン |
|
|
| 有料プラン |
|
|
無料プランは、基本的な音声認識機能を利用できる一方で、いくつかの制約があります。
処理できる音声ファイルの長さやサイズに制限があり、サポートも限定的です。
有料プランでは、長時間の音声ファイルの処理が可能であり、認識精度も向上します。
また、ノイズキャンセル機能や多言語対応など、プロフェッショナルな用途に適した機能も使用できるようになります。
さらに、有料プランでは優先サポートが提供されるため、技術的な問題が発生した場合でも迅速に対応してもらえるのが大きな利点です。
自分にあったプランの選び方
個人利用や小規模プロジェクトの場合、基本的な音声認識機能や短い音声ファイルの文字起こしに対応しているため、無料プランでも十分に対応可能です。
一方有料プランでは、ノイズキャンセル機能や多言語対応、優先サポートが提供されるため、ビジネス用途や大規模プロジェクトに適していて。
長時間の音声ファイルを頻繁に扱う、または高精度な認識技術が必要な場合は、有料プランを使う事で時間の軽減や人件費削減などメリットもあります。
自分の使用頻度や具体的なニーズを把握し、最適なプランを選ぶことで、Whisperの機能を最大限に活用してみてください。
Whisperを利用するメリット

Whisperを利用する事で様々なメリットがあります。
- 高精度な音声認識が可能
- 多様な音声モデルを利用できる
詳しく解説していきます。
高精度な音声認識が可能
Whisperは、最新のディープラーニング技術を駆使しているため、高精度な音声認識を可能にしました。
この技術は、大規模なデータセットを用いたトレーニングにより、様々なアクセントや話し方に対する認識精度を向上させています。
Whisperの音声認識エンジンは、背景ノイズや話者の変化にも強く、リアルタイムでの音声認識も可能なため、ビジネス会議やオンライン授業、カスタマーサポートなど、即時に文字起こしが必要なシーンでも活躍します。
特に医療や法務の分野では、正確な記録が求められるため、Whisperの高精度な音声認識は非常に便利です。
多様な音声モデルを利用できる
Whisperは、多様な音声モデルを提供し、ユーザーのニーズに合わせた最適な音声認識環境を作ることができます。
標準的な音声モデルから専門的な用途に特化したモデルまで、様々なシナリオに対応可能です。
例えば、複数言語を話す環境では、多言語対応モデルが役立ちます。
Whisperの音声モデルは、ユーザーのフィードバックに基づいて継続的に改善されるため、常に最新の技術を使用することが可能です。
Whisperを利用するデメリット

Whisperを利用する事で様々なデメリットがあります。
- API利用にはコストが発生する
- 多高いハードウェア要件が必要
詳しく解説していきます。
API利用にはコストが発生する
WhisperのAPIを利用するには、無料プランでは基本的な音声認識機能を試すことができますが、本格的な運用や高度な機能を利用するためには有料プランの導入が必要になってきます。
有料プランは月額制や従量課金制が一般的で、使用量に応じた料金が設定されています。
このコストは、提供されるサービスの質やサポートの充実度に比例しています。
しかし、業務効率の向上や人件費の削減、品質の向上といったメリットを考慮すると、十分に価値のあるものです。
高いハードウェア要件が必要
Whisperを効果的に利用するためには、高いハードウェア要件が必要になります。
特に大規模な音声データのリアルタイム処理や高精度な認識を行う場合、高性能なCPUや大量のメモリ、GPUの活用がおすすめです。
しかし、高性能なハードウェアは初期投資が大きく、運用コストも高くなるため、負担になる事もありますよね。
その場合クラウドベースのサービスを利用することで、必要なときに必要なリソースだけを使用し、コストを抑えることができます。
Google Colaboratoryなどの無料や低コストで利用できるクラウド環境を活用することで、高いハードウェア要件を満たしながら、効率的にWhisperを利用することが可能です。
音声認識AI「Whisper」についてよくある質問
[su_box title=”音声認識AI「Whisper」についてよくある質問” box_color=”#339FDB”]
- Whisperの文字起こしはリアルタイムで可能?
- Whisperの文字起こしには時間がどれくらいかかる?
[/su_box]
whisperに関してよくある質問とその解決策について解説していきます。
Whisperの文字起こしはリアルタイムで可能?
リアルタイムでの文字起こしが可能です。
発言内容を瞬時に記録し、リアルタイムで共有することができます。
ただし、リアルタイム文字起こしの精度は、音声の品質や背景ノイズの有無、話者のアクセントなどに依存するため、最適な環境での使用がおすすめです。
高性能なハードウェアや安定したインターネット接続があると、よりスムーズなリアルタイム文字起こしができます。
Whisperの文字起こしには時間がどれくらいかかる?
Whisperの文字起こしにかかる時間は、音声ファイルの長さや内容、システムの処理能力によって異なります。
一般的には、1時間の音声データを文字起こしする場合、数分から十数分程度の処理時間が必要です。
時間を短縮したい場合、高性能なハードウェア等を使用する事で改善することができます。
Whisperはローカル環境で文字起こしが可能?
Whisperはローカル環境でも文字起こしが可能です。
ローカル環境での文字起こしは、インターネット接続が不安定な場所でも使用することができ、クラウドベースのサービスと比べてデータのセキュリティが確保されるため、機密情報を取り扱う業務にも適しています。
ローカル環境での利用には、PythonがインストールされたPCと必要なライブラリが必要になります。
まとめ:Whisperで文字起こしを行ってみましょう
whisperの技術が大幅に進化し、文字起こしの精度が飛躍的に向上しました。
特に日本語の音声認識においては、従来の課題であった方言や専門用語の認識精度が劇的に改善されています。
これにより、ビジネスシーンや教育現場でも「whisper」の導入が進み、効率化が図られています。
まだwhisperを利用したことがない人はぜひ活用してみてください。
[su_note note_color=”#FEFFE0″]
なお、最新AIを使って効率的にブログ記事・SEOコンテンツを作成したいのであればAItoolsを利用するのがおすすめです。
今なら5日間の無料トライアルもご用意しているので、AIライティングに興味がある人はぜひチェックしてください。
[/su_note]